
yolov5
Blogs:
Batch
Video:
The number of the samples in a group been trained.
As a result, the training speed was largely improved by a large batch. But at the same time, the performance of the model might decreased.
- small batch → Less accurate
- large batch → computer time and over fit the dataset
- batch size of 32 or 64 is a good starting point
Epochs
The times of back-forward
Exp:
Sampel: 3000
BatcCh 32
epochs: 500
- 32 samples will be taken at a time to train the network
- To go through all 300 samples it takes 3000/32 = 94 iterations → 1 epoch.
- This process continues 500 times (epochs).
Practice
Youtube:
Blog with data set:
My experience
Train a small group of data set
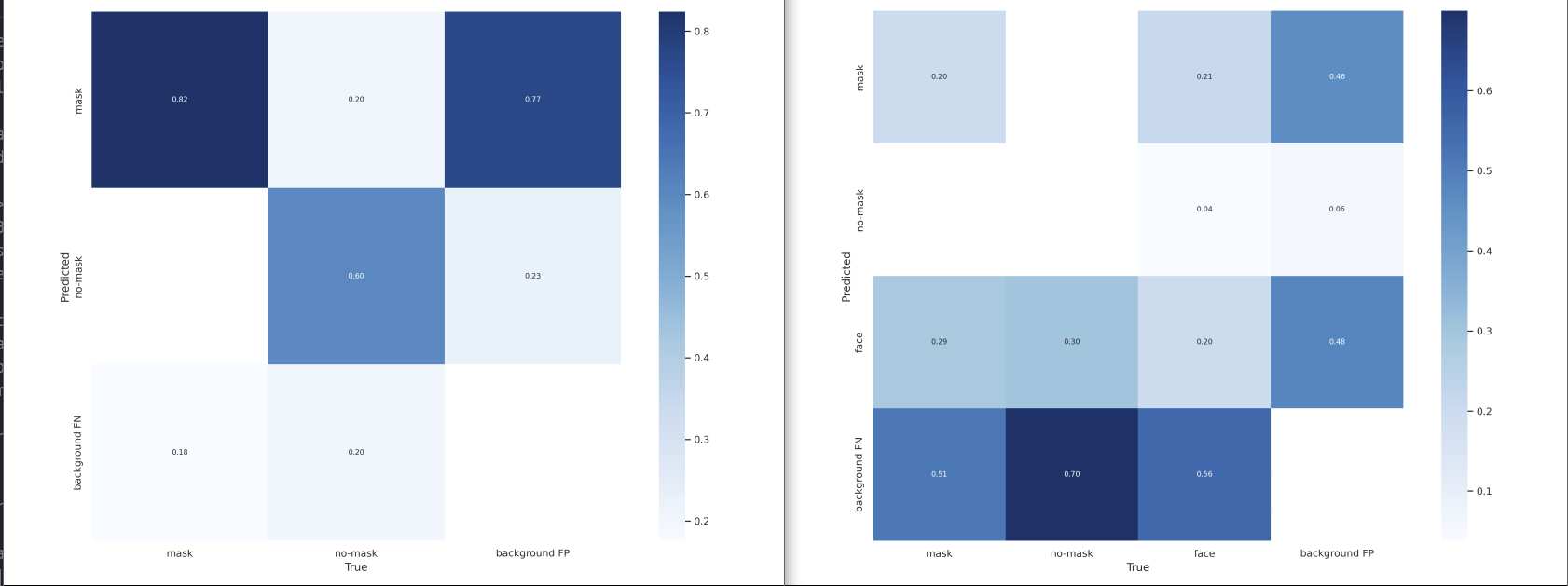
Some blogs suggest that we should avoid to label one thing multiple times. I want to know how really it affects. I found a small set of data which has only 105 imgas in trainning set. They labeled two classes as mask-on and mask-off. For testing, I’ll repeat all labeles as class 3 which stands for face. After trainning with the same arguments, both model would be used to detect the test dataset and results would be recorded.
Aruguments for training with two GPU
|
Script for repeat the labels.
PS:
There is a very important features for yolov5: if the location of two labels are identical, one of the class would be deleted.
At the first time, I just simpliy duplicate all boxs and change the class into a new one. After training, results shows that there are no single labeled face in the training set. So, I have tried to add 0.0001 into each location for make the class ‘2’ different from the origin one.
|
805 1743
As you can see, before the repeat, there are 805 targets. After repeat the labels, we’ll update the label information in data.yaml
|
nc: 3 names: ['mask', 'no-mask', 'face']
Detacte and result extrect
|
The result:
| Class | Model1 | Model2 | Truth |
|---|---|---|---|
| mask | 595 | 570 | 573 |
| no_mask | 131 | 110 | 123 |
| face | 0 | 646 | 687 |
As you can see, from the result 1
Advice for Best Training Results
First, please read the Tips for Best Training Results
-
First thing frist: Label the target well! This is the key step for all work.
-
Large batch as you can!
-
Chech the result, try to increasing the epecho as yor “val/obj_loss” didn’t increase







