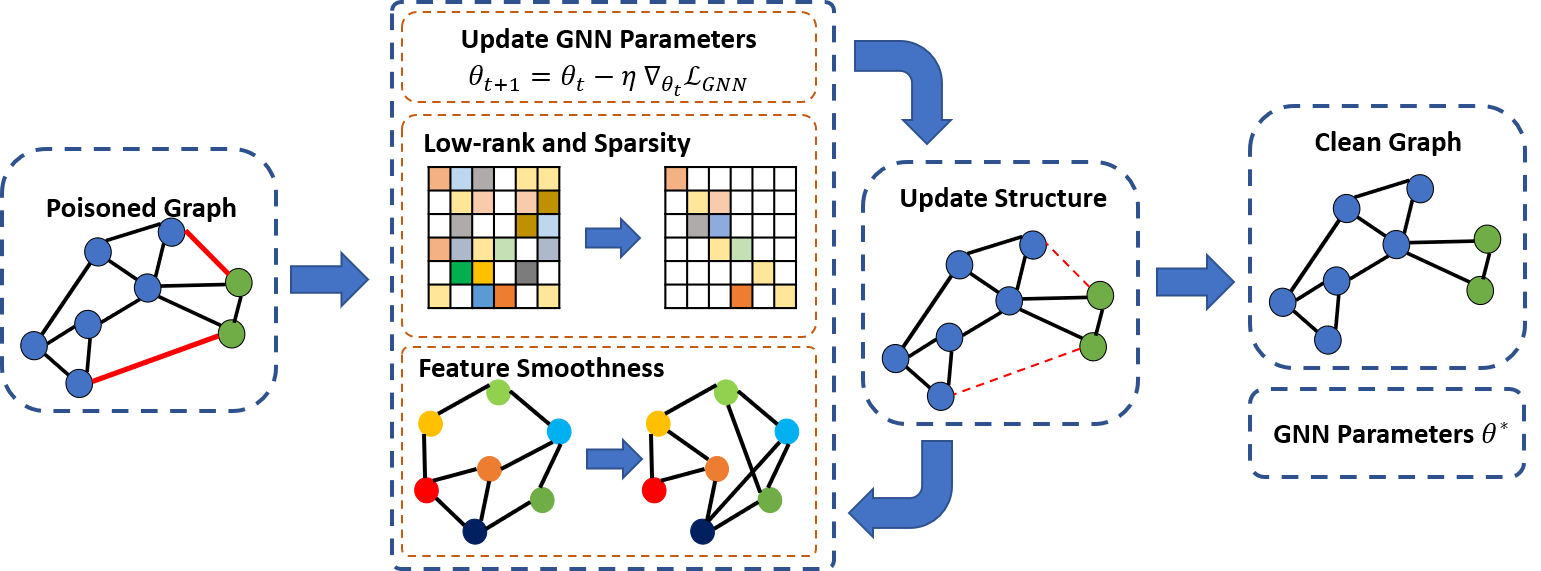
GNN: Graph Neural Networks
Graph Neural Networks (GNNs)
Strong suggest to read: A Gentle Introduction to Graph Neural Networks; Adam Pearce, et al.; distill; 2021
A Graph Neural Network (GNN) is a type of deep learning model designed to operate directly on graph-structured data by iteratively “passing messages” along edges: each node maintains a feature vector, exchanges information with its neighbors through learnable aggregation functions, and updates its embedding to capture both local connectivity and node attributes; by stacking multiple such layers, a GNN can learn representations for individual nodes (e.g., for node classification), entire graphs (e.g., for graph classification), or edges (e.g., for link prediction), making it highly effective for any task where relationships between entities matter.
!!! Pure Personal Understanding for Quick Understanding the GNN
For CNN, after multiple rounds of convolution by using different kernel like Alex net, the 2D image is encoded into a single vector. So as the GNN. For graphic data, we sort the layers of each nodes based on the graphic sctrcutre. Then we convlution the nodes by using the same kernel which included the nodes from the next layer. The nodes would updated as the sum of nodeweight(nodes adjacent). If there are attention, the attention are further included. Finally, then entire graphic data would be encoded into a single vector as input according to the features. The most straight forward way is take the sum/mean value of all encoded nodes as the final graph representation. During the training, the weight used in the nodes update are update. The attention are also a learnable parameter. Because the vector then input into the neural network, the next steps work exactly the same as CNN.
Basic for GNN
Adjacency
The adjacency matrix (A) is a square matrix used to represent a finite graph. The elements of the matrix indicate whether pairs of vertices are adjacent or not in the graph. For an undirected graph, the adjacency matrix is symmetric.
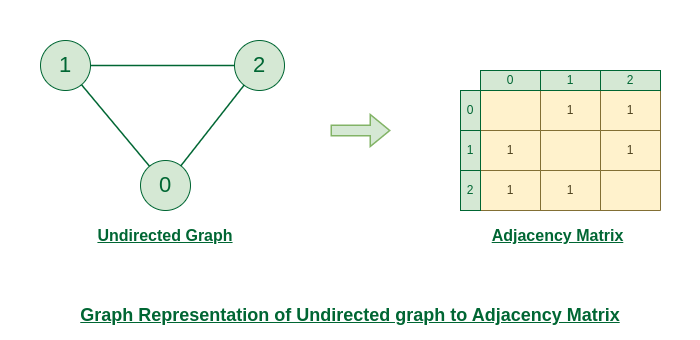 |
|---|
| © geeksforgeeks; for more, click here |
Simple Information Passing
$$
\mathbf{x}^\prime_i =\ \bigoplus_{j \in \mathcal{N}(i)} e_{ji} \cdot \mathbf{x}_j
$$
SimpleConv is a non-trainable message-passing operator in PyTorch Geometric that simply propagates (and optionally weights) neighbor features:
- $\bigoplus$ is the aggregation operator you choose (
sum,mean,max, etc.). - $e_{ji}$ is an edge weight (if provided) or 1 by default.
- It does not learn any linear transforms—it just spreads information across the graph ([PyTorch Geometric][1]).
Key Parameters
-
aggr(strorAggregation, default='sum'):
How to combine messages from neighbors. Options include"sum","mean","max","min","mul", or a customAggregationmodule ([PyTorch Geometric][1]). -
combine_root(str, optional):
If notNone, specifies how to combine the central node’s own feature with the aggregated neighbor message. Choices:"sum": add $\mathbf{x}_i$ to the aggregated message"cat": concatenate $\mathbf{x}_i$ with the aggregated message"self_loop": treat self-loops just like any other edgeNone(default): ignore the root feature ([aidoczh.com][2]).
2. Basic Usage Example
|
# tensor([[4.], # [4.], # [4.]], grad_fn=) # Explanation: each out[i] = sum of neighbors + x[i]: # out[0] = x[2] + x[0] = 3 + 1 = 4 # out[1] = x[0] + x[1] = 1 + 2 = 3 (oh—and since combine_root='sum', you get +2 again → 4) # out[2] = x[1] + x[2] = 2 + 3 = 5 (plus x[2]=3 → 8)
3. Using Edge Weights
If your graph has edge weights, pass them in as a third argument:
|
tensor([[1.5 ], # 0’s only neighbor is 2, so 2*0.5 = 1.5
[0.5 ], # neighbor 0 with weight 0.5 = 0.5
[2.0 ]]) # neighbor 1 with weight 1.0 = 2.0
4. Integrating into an nn.Module
Typically you’ll wrap it in a small GNN:
|
Why work it in this way?
Applying F.relu and then a trainable Linear layer lets the model learn useful, non‐linear combinations of the propagated features:
SimpleConvis purely linear: it just averages or sums neighbor features (possibly weighted), but has no trainable parameters (beyond edge weights if you supply them).F.reluadds non-linearity: without it, stacking another linear operation would collapse into a single linear transformation. The ReLU ensures the network can learn more complex functions of the aggregated features.Linearlearns the final mapping: you typically want to transform your hidden node features into whatever target space you need (e.g. class logits, embedding space, regression value). TheLinearlayer is where the model’s weights get updated to solve your specific task.
Putting it together:
|
This pattern—(propagate) → (non‐linearity) → (trainable transform)—is the bread-and-butter of deep GNNs.
When to Use SimpleConv
- As a quick propagation step (e.g., label propagation) without extra parameters.
- As a baseline to test how much plain feature diffusion alone helps your task.
- In combination with trainable layers (like
Linear) to control which parts of the network actually learn.
Laplacian
spectral insights
GNN: Graph Neural Networks







