Python 爬虫 – 新闻爬取
1. 科技快讯
网址:http://www.citreport.com/
以科技快报为目标
1. 首先, 获取整个页面信息
from bs4 import BeautifulSoup"http://www.citreport.com/" ).read ()'lxml' )
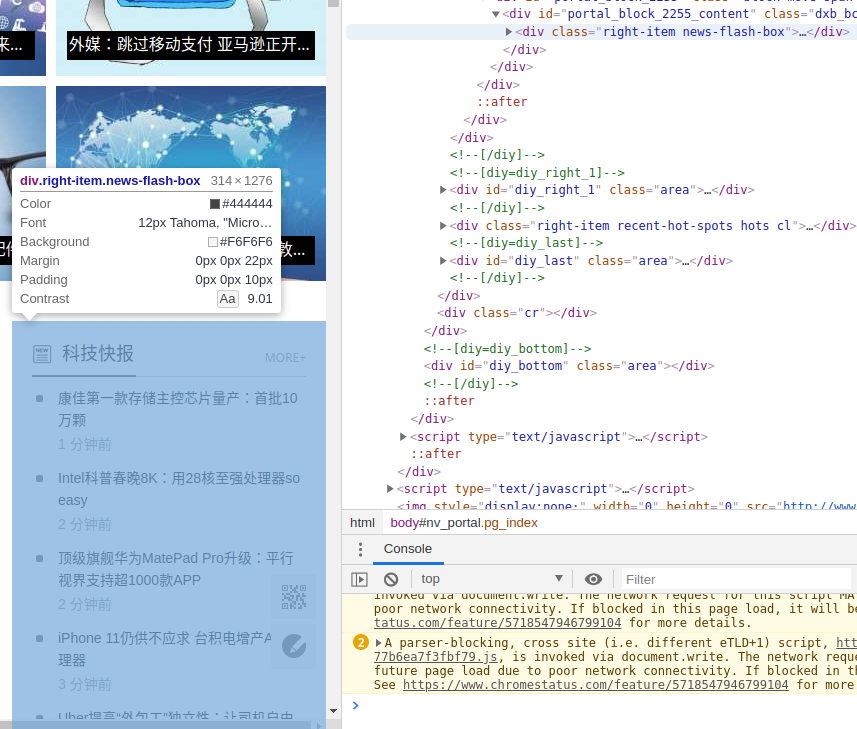
2. 查看网页源码
ctrl+shit+c 查看网页源码
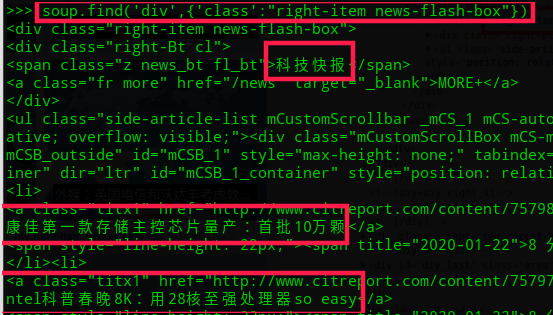
3. 复制框内的信息, 匹配一下:
Paper = soup.find('div' ,{'class' :"right-item news-flash-box" })print (Paper.get_text())
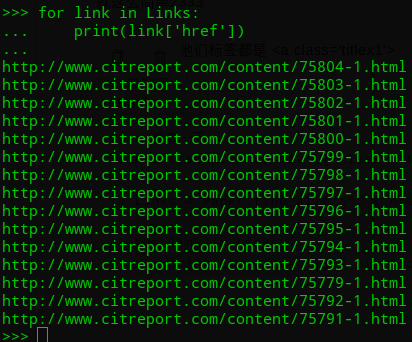
4. 获取快讯文字链接
'div' ,{'class' :"right-item news-flash-box" }).get_text())"a" , {"href" : re.compile ('http://..*?\.html' )})for link in Links:'href' ])
成功获得快讯文字的链接
5. 以第一篇为模板进行文章抓取
url = Links[1 ]['href' ]'lxml' )
6. 继续查看码源, 获取标题和文字格式
发现,标题的标签为:<br /><h1 class="ph"
文章主题标签为:<br /><div class="d">
则,代码如下
P_title = soup.find('div' ,{"class" :"h hm cl" }).get_text()'td' ,{"id" :"article_content" }).get_text()
这就成功啦
7. 整合一下,并且, 循环抓取本小模块的所有paper
from bs4 import BeautifulSoup"http://www.citreport.com/" ).read ()'lxml' )'div' ,{'class' :"right-item news-flash-box" })"a" , {"href" : re.compile('http://..*?\.html' )})for link in Links:'href' ]read ()'lxml' )'div' ,{"class" :"h hm cl" }).get_text()'td' ,{"id" :"article_content" }).get_text()print (Paper)
2 NPR News Head Line
from bs4 import BeautifulSoup"https://www.npr.org/" read ().decode('utf-8' )'lxml' )'div' ,{"class" :"story-wrap" })"" for i in story_today:
3. 爬取B站空间主页信息
参考: https://zhuanlan.zhihu.com/p/34716924
import astfrom urllib.request import urlopenimport time"86328254" "http://api.bilibili.com/archive_stat/stat?aid=" + ID'utf-8' )'data' ]"观看量: " + str (Cont['view' ])"点赞: " + str (Cont['like' ])"回复: " + str (Cont['reply' ])"硬币: " + str (Cont['coin' ])"\n" .join([View, Like, Reply, Coin])