
Find Dead Links in Your Blog/Website
Find Dead Links in Your Blog/Website
Links may die from time to time. For example, some posts might be deleted, some old servers may be shout-done, some links dead because the host transplanted to another platform. These dead links may damage your website’s rankings and usability. So, it is important to check and delete them periodically.
Dead Link Checker
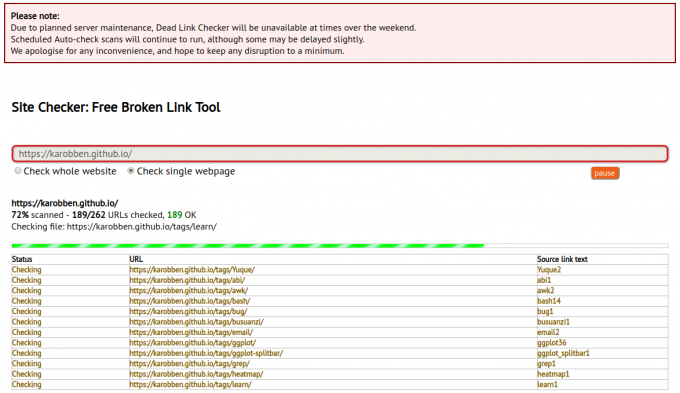
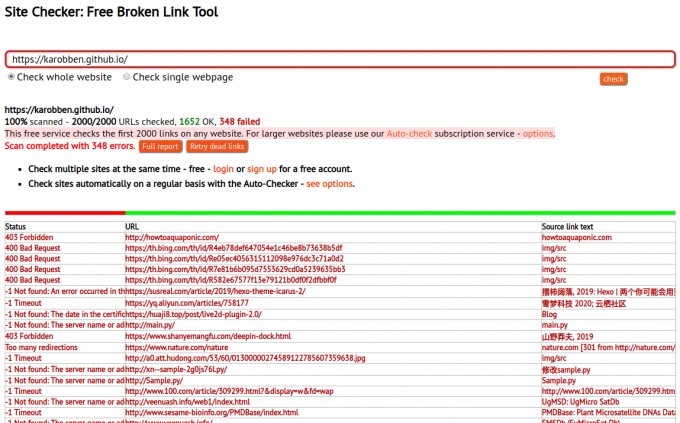
This is one of the most friendly and powerful tools for dead link check!
You can check a single page or Whole Website at a time.
You can check the first 2000 links on our website. But for more services, you must subscribe to achieve advanced applications.
| Chick the single page | Chick the website |
|---|---|
 |
 |
Deleted the Deadlinks
|
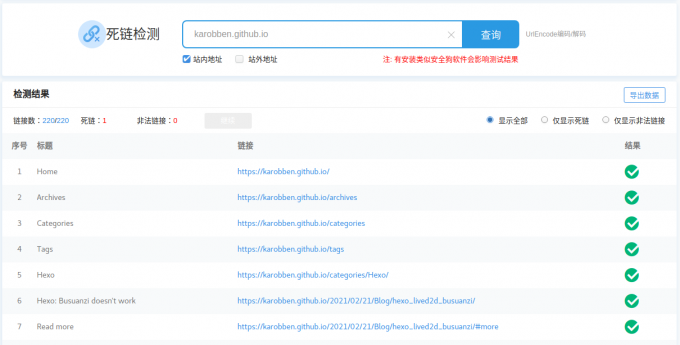
站长工具
This tool can only check a single page.
Local Dead Link Check
Python
Deadlinks
GitHub: butuzov
|
| © butuzov |
I am currently running this version:
Name: deadlinks Version: 0.3.2 Summary: Health checks for your documentation links. Home-page: https://github.com/butuzov/deadlinks Author: Oleg Butuzov Author-email: butuzov@made.ua License: Apache License 2.0 Location: ~/.local/lib/python3.7/site-packages Requires: reppy, six, click, requests, urllib3 Required-by:
But it is easy to cease when we have too many deadlinks.
So, I’d like to add a timeout argument. But I failed.
By checking the command, we know taht the main function is __main__.py
|
## -*- coding: utf-8 -*-
import re
import sys
from deadlinks.__main__ import main
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(main())
So, let’s check the (part of codes) __main__.py:
|
It looks like it is checking the web with the function crawler and arguments are stored at **opts which handled by Settings
Write your tools
For my example, all my html are in the directory of public.
So, my strategist is:
- find all
<a>tags (grep) - remove redundant part (
awk) - sorting all
href(sort|uniq) - filter reliable links
|
Then, run another script
|
Find Dead Links in Your Blog/Website







