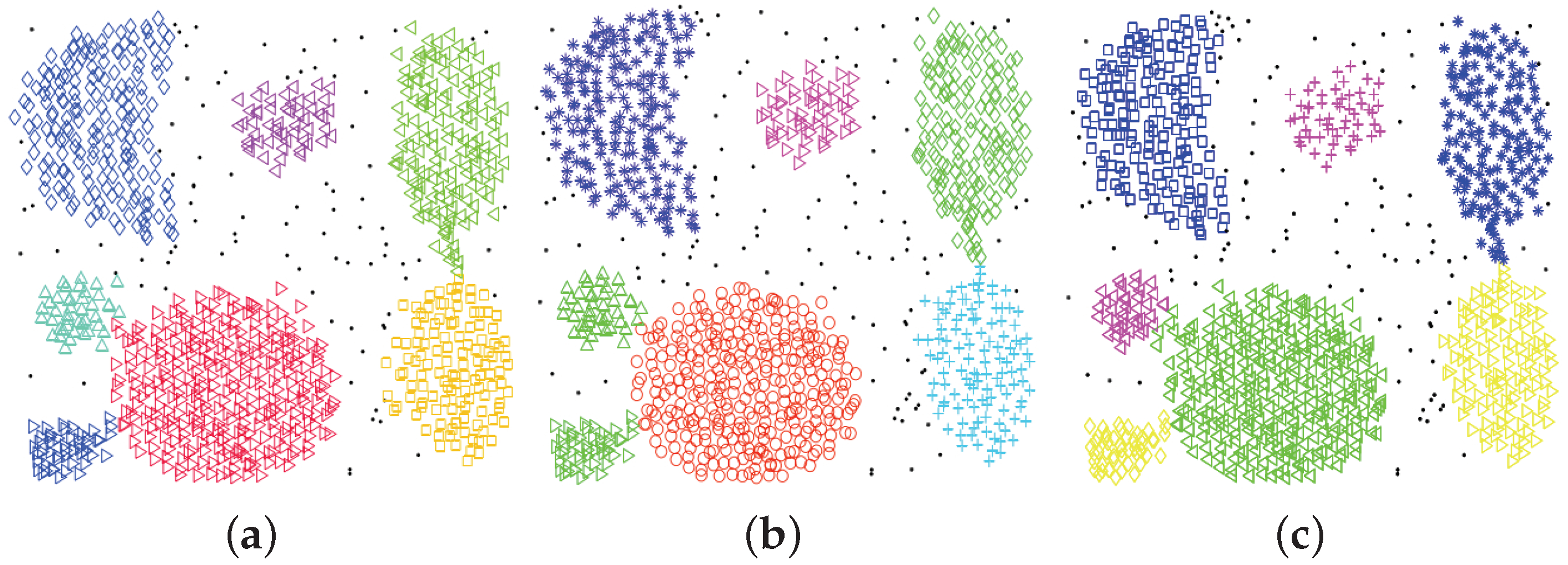
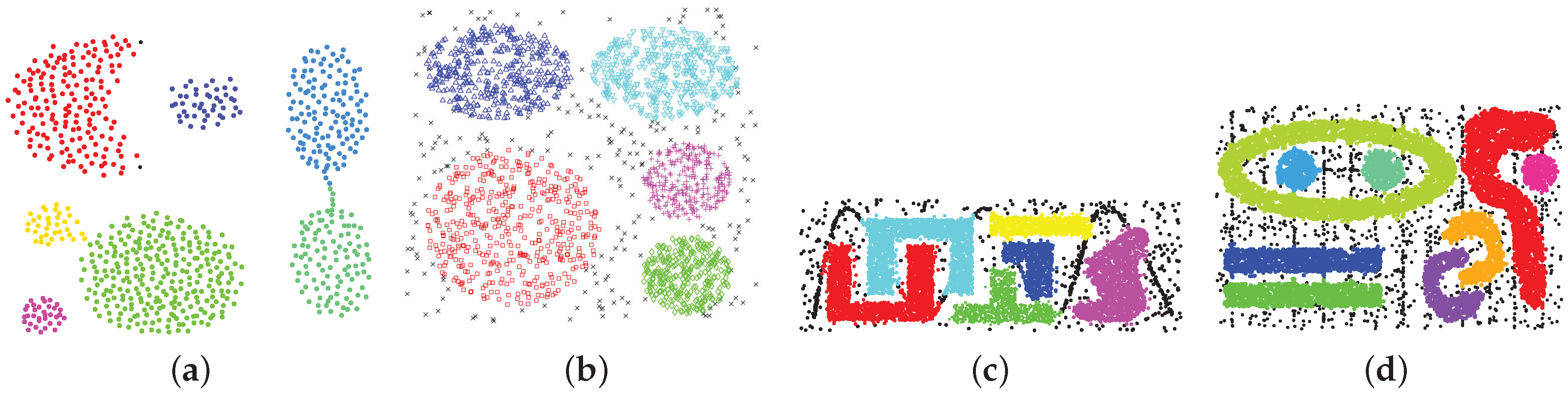
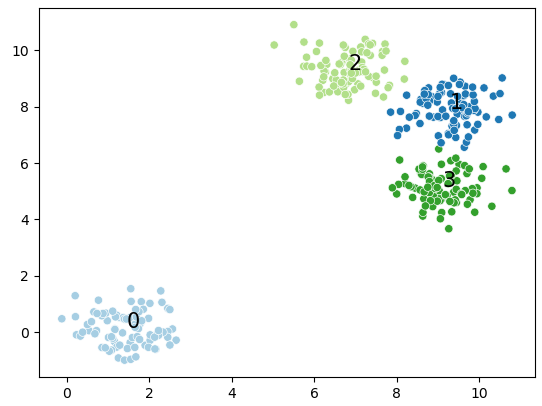
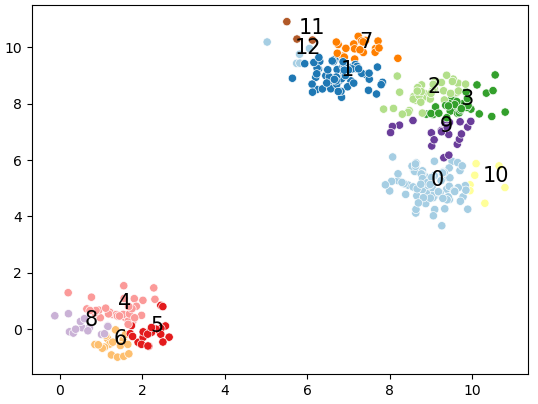
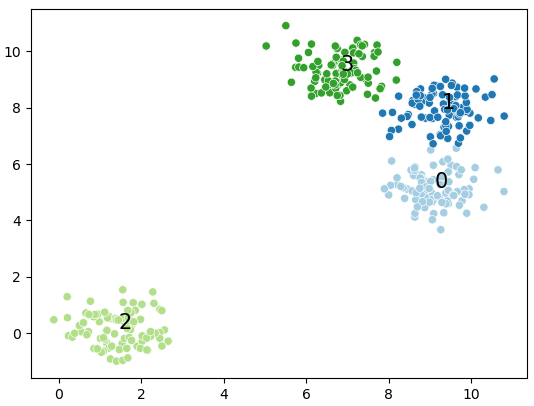
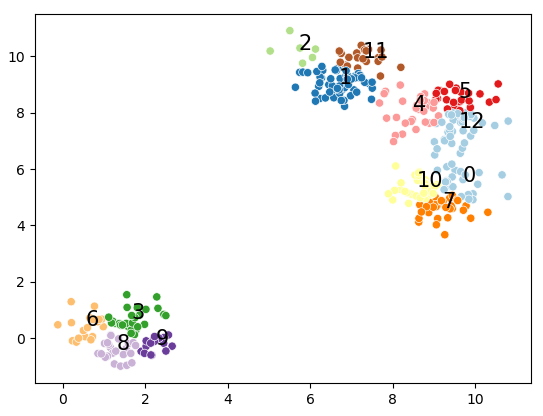
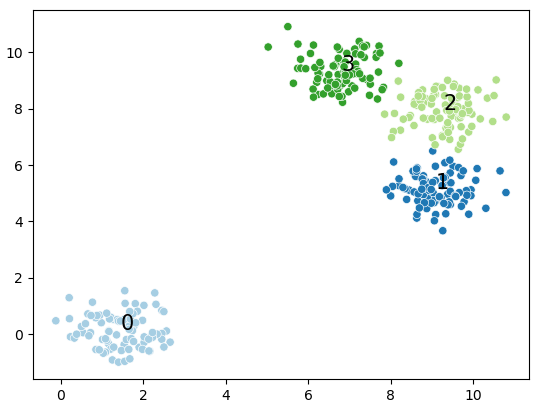
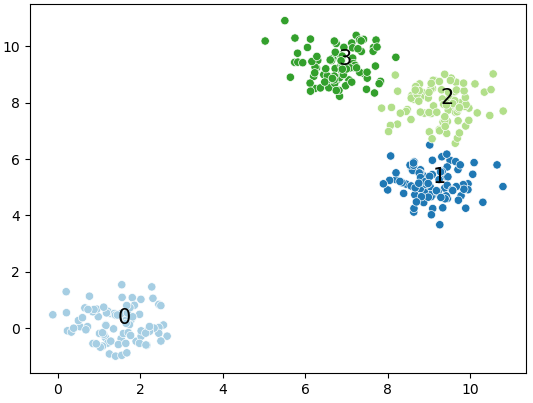
DBscan is cluster a group of nodes by the spatial distribution density.
It divided the nodes to “core point”; “border point”, and “outlier point”
By given the pre-assigned diameters (of the sphere) and number of the adjacent nodes, it scan the nodes randomly.
The node fit our expectation is core node.
The node failed to achieve the expectation but adjacent to the core point(a) is border point.
Rest of nodes are outlier points
The advantage of DBscan is
Outlier points (Noises) is tolerated. (Unlike k-means)
It can detect the cluster under a cluster. (Not like spherical-shape cluster)
source:scikit-learn.org
preferencearray-like of shape (n_samples,) or float, default=None
Preferences for each point - points with larger values of preferences are more likely to be chosen as exemplars. The number of exemplars, ie of clusters, is influenced by the input preferences value. If the preferences are not passed as arguments, they will be set to the median of the input similarities.
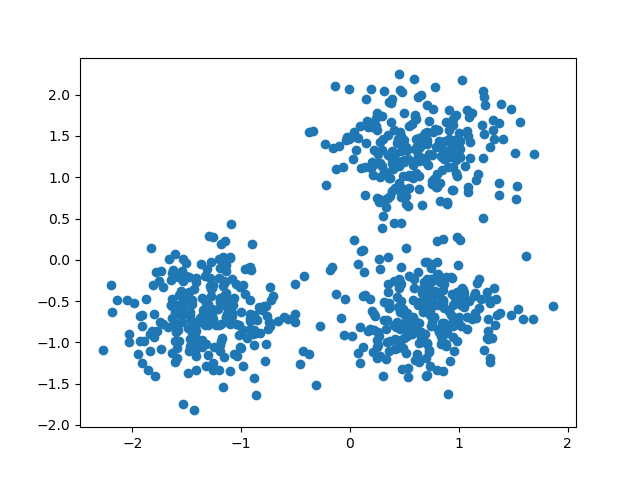
import numpy as np import seaborn as sns from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import AffinityPropagation
X, y = make_blobs(n_samples=350, centers=4, cluster_std=0.60)
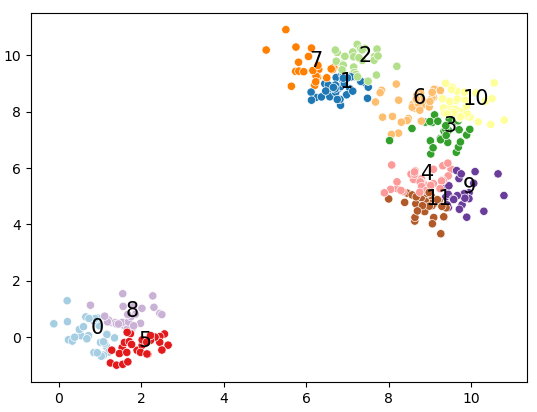
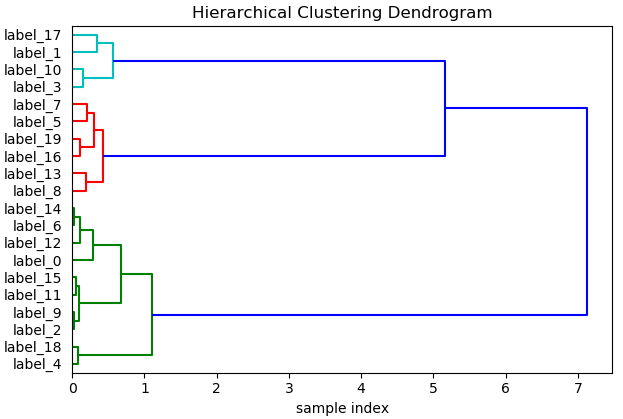
from scipy.cluster.hierarchy import dendrogram, linkage import scipy.stats as stats from scipy.cluster.hierarchy import cophenet from scipy.spatial.distance import pdist from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=350, centers=4, cluster_std=0.60) XX= X[:20]
Z = linkage(stats.zscore(XX) , 'ward') c, coph_dists = cophenet(Z, pdist(XX)) label = ["label_" + str(i) for i inrange(len(XX))]
temp = {ii: label[ii] for ii inrange(len(label))} defllf(xx): return temp[xx]
Z = linkage(stats.zscore(XX) , 'ward')
plt.title('Hierarchical Clustering Dendrogram') plt.xlabel('sample index') plt.ylabel('distance') dendrogram( Z, orientation='right', leaf_label_func=llf, leaf_rotation=0., # rotates the x axis labels leaf_font_size=10., # font size for the x axis labels ) plt.show()
Unsupervised Machine Learning in Python (DBSCAN; UMAP, t-SNE, etc)