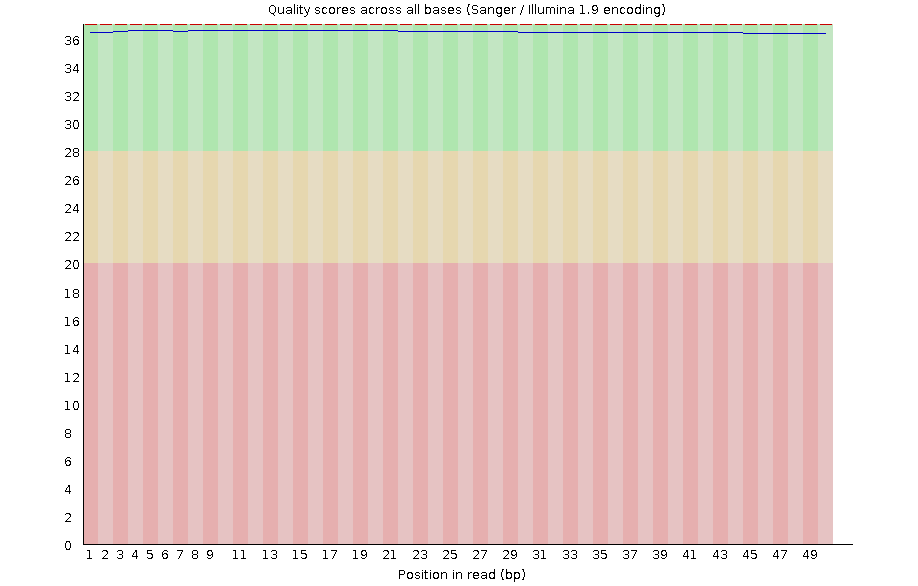
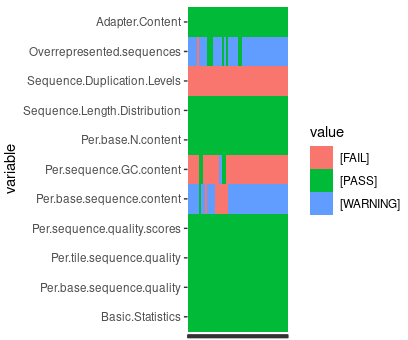
When dealing with a large number of samples, it’s crucial to conduct quality control (QC) and scrutinize the results to identify any outliers. Filtering out low-quality data can significantly influence subsequent processes. Below is an example illustrating how we use all QC results from FastQC for cluster analysis.
Summary information collect
import os import pandas as pd from bs4 import BeautifulSoup
defTab_grep(Sample): html = open(Sample).read() soup = BeautifulSoup(html, features='lxml') Summary = soup.find_all('div',{"class":"summary"})[0] Reu_l = [Sample] Cla_l = ["Sample"] for line in Summary.find_all("li"): Cla_l += [line.get_text()] Reu_l += [str(line).split('"')[1]] Result_TB = pd.DataFrame([Reu_l], columns=Cla_l) return Result_TB
Result_TB = pd.DataFrame() for Sample in [i for i in os.listdir() if"fastqc.html"in i]: Result_TB = pd.concat([Result_TB, Tab_grep(Sample)])
import os import pandas as pd from bs4 import BeautifulSoup
defPic_save(Sample, OUT="/home/wliu15/OUT.md"): html = open(Sample).read() soup = BeautifulSoup(html, features='lxml') F = open(OUT,"a") F.write(Sample+"\n") F.write(str(soup.find('h2',{"id":"M5"}))) F.write(str(soup.find('img',{"alt" : "Per base sequence content"}))) F.close()
for Sample in [i for i in os.listdir() if"fastqc.html"in i]: Pic_save(Sample)
Overrepresented Sequences
import pandas as pd
TB = pd.DataFrame() for Sample in [i for i in os.listdir() if"fastqc.html"in i]: iflen(pd.read_html(Sample))!=1: TMP = pd.read_html(Sample)[1] TMP['Sample'] = Sample TB = pd.concat([TB, TMP])