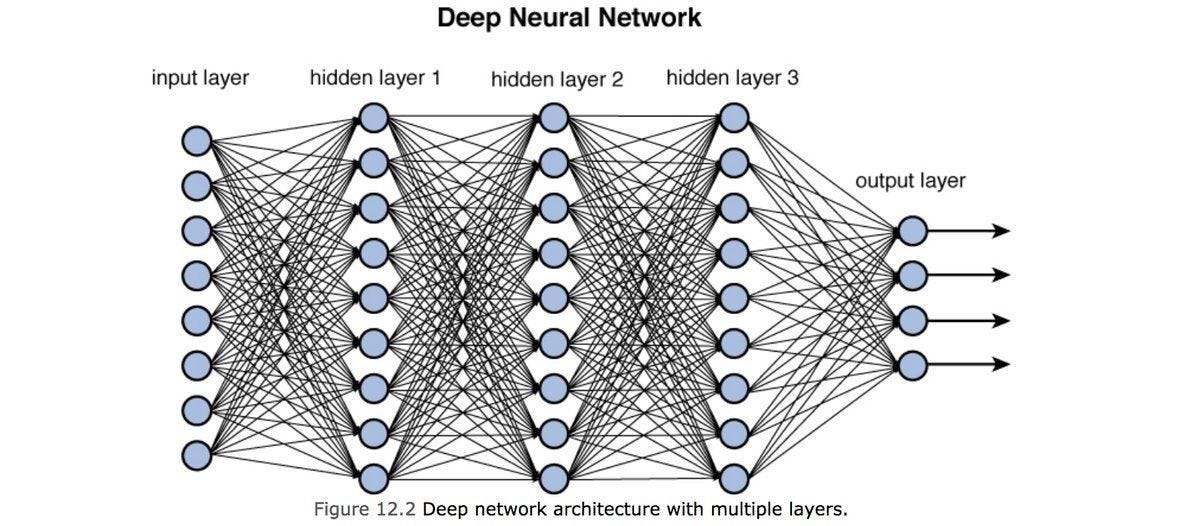
torch: Start with Deep Learning
Torch: Start with Deep Learning
Mostly from ChatGPT4
|
How to use GPU for training
- 首先,检查你的系统是否支持CUDA(即GPU计算):
|
- 然后,将模型转移到GPU:
|
- 然后,将模型转移到GPU:
|
- 同样,当你进行预测时,也需要确保数据被转移到了GPU:
|
保存和继续训练
- 保存整个模型:
torch.save(model, 'model.pth') - 只保存模型参数:
torch.save(model.state_dict(), 'params.pth') - 加载整个模型:
model = torch.load('model.pth') - 只加载模型参数:
model.load_state_dict(torch.load('params.pth'))
|
torch: Start with Deep Learning







