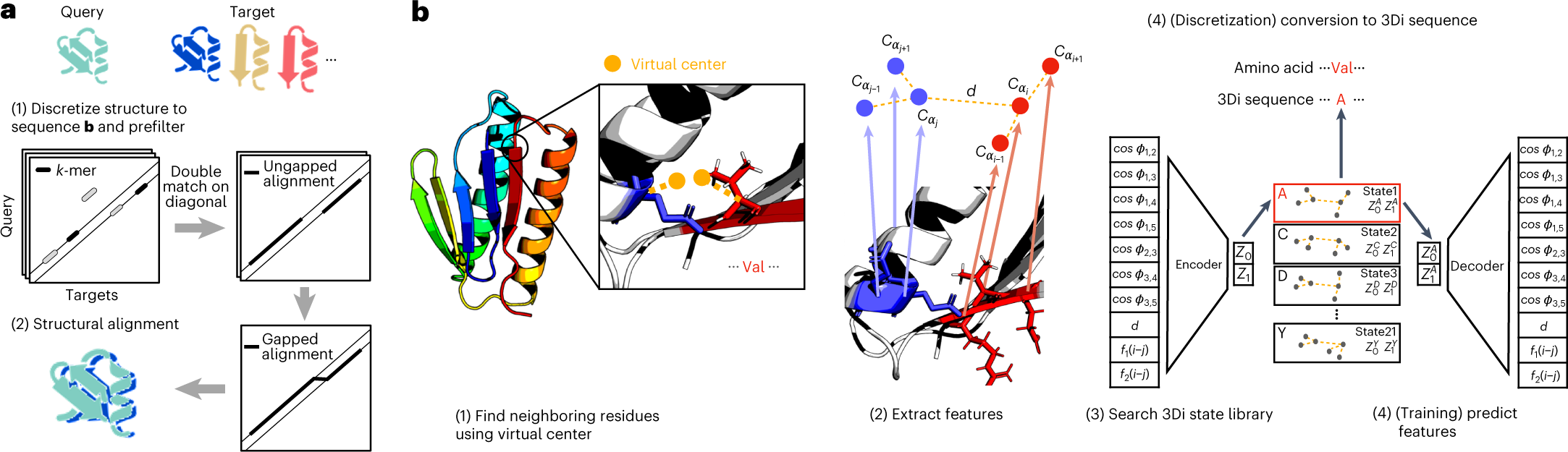
Rosetta, the Pioneer of Protein Structure Prediction
Rosetta is a comprehensive computational suite that plays a pivotal role in the protein folding field by predicting and designing protein structures based on amino acid sequences. It employs a combination of physics-based energy functions and advanced algorithms, such as fragment assembly and Monte Carlo sampling, to simulate the folding process and explore the vast conformational landscape of proteins. By iteratively optimizing potential structures, Rosetta helps researchers identify low-energy, stable configurations that closely resemble naturally occurring proteins. This tool not only aids in elucidating fundamental principles of protein structure and function but also supports the design of novel proteins and therapeutic interventions, making it an indispensable resource in structural biology and bioengineering.
Read more