ESM (Evolutionary Scale Modeling) is a family of large-scale protein language models developed by Meta AI. They’re trained on massive protein sequence databases, learning contextual representations of amino acids purely from sequence data. These representations—often called embeddings—capture both structural and functional clues.
In practice, you feed a protein sequence into ESM to obtain per-residue embeddings, which you can then use for downstream tasks like structure prediction, function annotation, or variant effect prediction. If you batch multiple sequences together, ESM aligns them by adding special start/end tokens and padding shorter sequences to match the longest one. You then slice out the valid embedding region for each protein, ignoring any padding.
Read more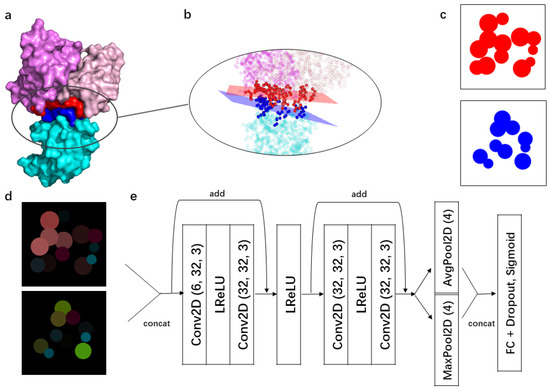 © Karobben
© Karobben © Karobben
© Karobben © Karobben
© Karobben