0Posted Updated R / Bio / Abi11 minutes read (About 1699 words)
Machine Learning in Action: ab1 file
Machine Learning in Action: ab1 raw data
At present, I’m working for a DNA sequencing company.
The experiment is not hard for me. But the head-breaking part is analyzing the results for a freshman: there are so many!
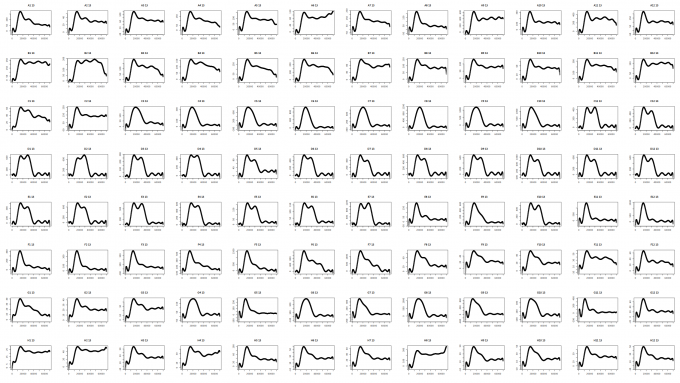
Traditionally, we can use Sequencing Analyzing to view the signal of electrophics. But there are 96 wells for each plate, and we have several plates in each day. It is hard to imagine checking the graphics one by one especially we have work to do.
For solving this problem, I tried R and python both. But ggplot2 is just fucking slow for massive data (As we know, for each plate, there are 96 wells. Each well has 4 signal tunnels, and each tunnel contains about 17,000 check-point. As a result, there are about 6.5 million points to plot). It takes about 2 mins for R to collect all matrix, plot, and save it. But python works much fluently.
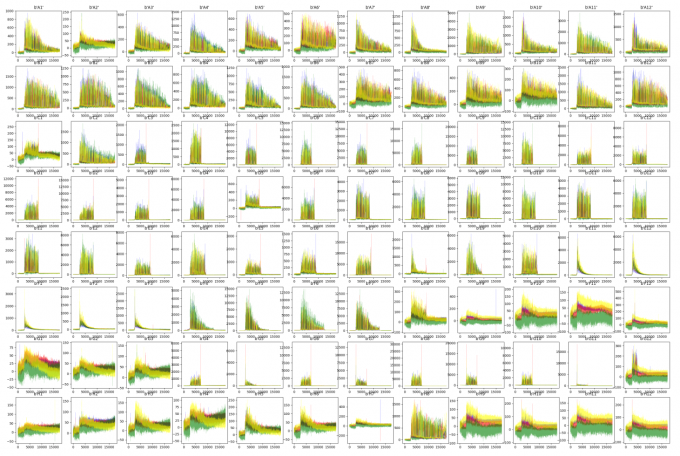
Let’s see an example of the plot.
Familiar with Your Data
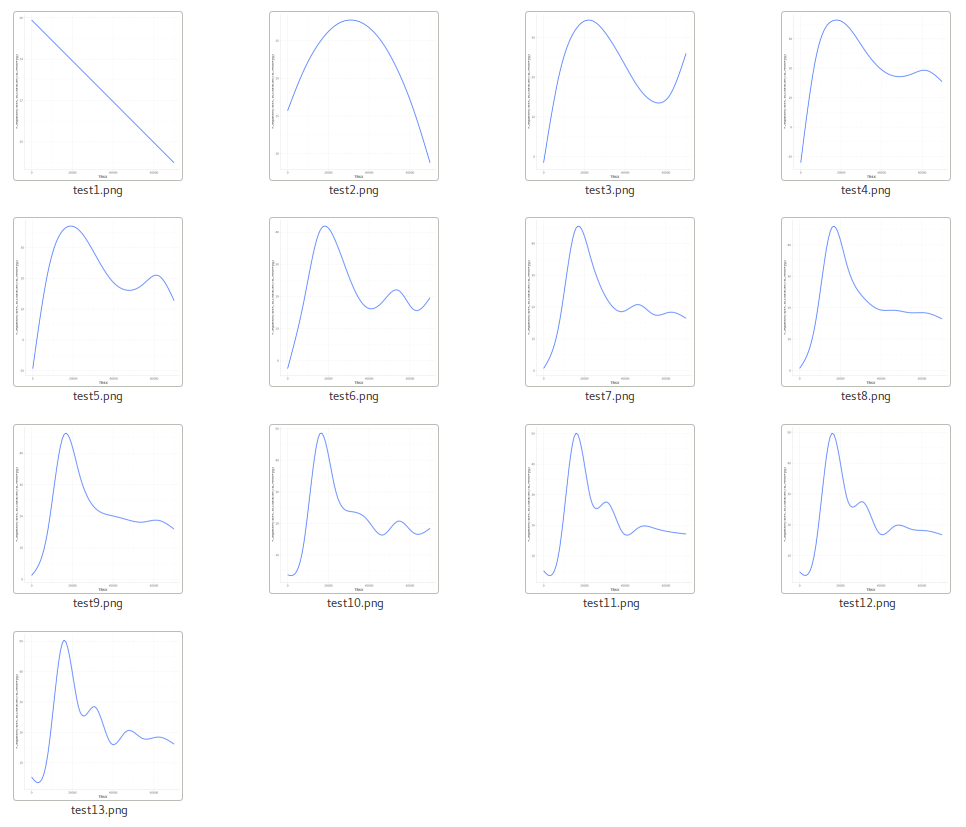
As we can see the result below, we have few types of pattern judged by the naked eyes:
A01: Triangle. (The signal is decreasing but is still readable)
A02: Flat. (Which doesn’t have signal at all)
A08: Laying-Trapezoid. (The perfect result we’d love to)
F01~F07: Acute Triangle. (Which means the signal is decreasing and the result is unreadable)
C02: Stick. (Short sequence or Signal-Break due to some reasons.)
Though, it is easy to acquire a model from ML by putting all those check-point into a matrix and training them. But I decided to reduce the burden of my computer.
By first, I’d like to try something like linear regression.
Linear Regression
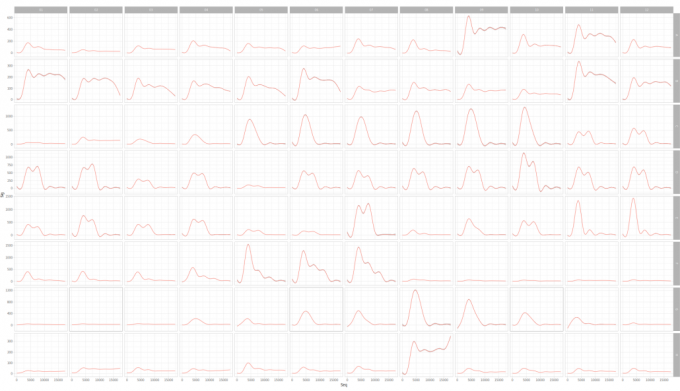
First, Let’s take a quick look of the smooth line
Now, let’s try the linear regression.
Main codes can be found at my blog
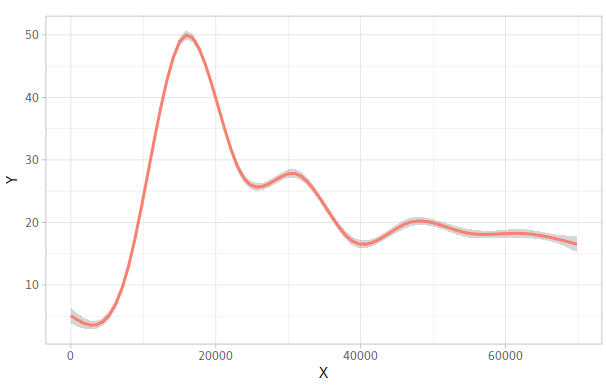
Let’s take the well H12 as an example
By using geom_smooth from ggplot2, we can achieve these graphics easily.
By calculating the regression function by lm with the exponent from 1 to 13, we can get the result as below An example of regression function:
As we can see, the last diagram is almost about the same as the result of geom_smooth!
Another awesome thing is it takes only a second to get the result!!
As we can see, the function of linear-regression is enough to tell us about that this well is failed or succeed and we can use the numbers from it to train our model!
Because I was trying to find a way to call bases from the raw abi file and failed, I using the Sequencing Analyzing software to made a post processing to get the sequence and quality grades of the bases. Once we have the quality matrix, we can have a better way to grade the result. My choice is calculating the mean value of the base-quality from 80 to 120 for several reasons:
120 base is enough to value a successful task.
first 80 bases have low quality and usually was tossed.
I’d like to collect the result though it’s a derogation-signal.
I choose R to achieve this because package sangerseqR can turn the quality grades to integer from bin16 format. And I don’t know how to achieve this in Python.
Read_abiDirector <- function(abi_director){ # Reading List abi_list = dir(abi_director) # Initialize Result TB <- data.frame() # Start flower for(abi_file in abi_list){ Plate = strsplit(abi_director,'/')[[1]][3] Well = strsplit(abi_file,'[.]')[[1]][1] abi_file = paste(abi_director,abi_file,sep="/") abi <- read.abif(abi_file) tmp <- data.frame(mean(abi@data$PCON.1[80:120]), Plate = Plate, Well = Well) tmp[[1]] <- tmp[[1]]/61*100 print(tmp) colnames(tmp) <- "Mean" TB <- rbind(TB,tmp) } TB[[1]][is.na(TB[[1]])] = 0 return(TB) }
Once We had the label file, we can extract the matrix one by one and turn them to xgb.matrix to train our model.
here, I removed the objective = "binary:logistic" parameter, and increased the depths and rounds to 5.
I combined 16 plates which means it has 1536 samples to compact the training data set.
Though, 5 rounds is not enough (fails ratio > 4%), I don’t want the model be over fitted.
Since the training data is better than before, I get the best performance for ever.